And saving the best until last, hello from Sheffield. We’re the fourth and final group to make our introductions; Gioia, who’s working with Linney, Mike who’s partnered with Costain and Rhiannon who’s using data provided by South Yorkshire Police to examine crime harm and hotspots.
The final module hosted in sunny Sheffield brought us all back together for the week. Working in RStudio the Social Analytics and Visualisation course utilised a wide range of expertise from a number of disciplines starting with data visulisation delivered by Dr Mark Taylor from the SMI in his inimitable style. We were then introduced to machine learning by Dr Petar Milin from the Department of Journalism and by midweek we were text mining as Prof Paul Clough from Sheffield’s iSchool introduced us through sentiment analysis using Trump’s speeches. We were then very fortunate to have Dr Nema Dean from the University of Glasgow’s School of Mathematics and Statistics take us through statistical social network analysis. This packed week was then rounded off with an opportunity to speak to lecturers one on one and leave the course confident about the assessment.
Before the new academic year starts we will have the opportunity to share our progress at an event hosted at LIDA where we will be discussing our work though posters and group presentations. We’ll also be meeting the new cohort of students and their data partners. As we move into the second year and the focus of our time is directed more towards our Phd’s we look forward to working more closely with our own data partners and using the skills we’ve developed through our MSc modules.
Welcome! We would like to introduce ourselves as the first cohort of the CDT in Data Analytics and Society at the University of Liverpool. Susie, who is working with Local Data Company on micro-location retail topologies. Nicola is working with Red Ninja using sensor data to analyse urban mobilities. Mel is working with Ordnance Survey on extracting data from aerial imagery. Nikos is also working with Ordnance Survey on defying neighbourhood trajectories in the UK. Krasen works with Carto on applying topology to urban data. Natalie is working with Boots on incorporating weather into sales forecasting methodologies. Céline is working with ShopDirect to examine the dynamics of pricing elasticities in the online retail environment.
We are a part of the Geographic Data Science Lab, (https://www.liverpool.ac.uk/geographic-data-science/ ) here at Liverpool’s Department of Geography and Planning. The lab researches many interesting topics, combining the fields of Data Science and Geography to develop innovative applications and outputs. Particular research themes include: urban and regional dynamics, the morphology of cities, investigating new methodologies and geographies of resilience, difference, exclusion and opportunity.
Last semester, we had the opportunity to undertake an internship with our partner companies. Collaborating on a research proposal laid the foundations for a healthy, communicable relationship with our partners, which we are excited to develop over the coming years of our PhDs. Some of us had the chance to work on our projects in-person in the company’s offices; a valuable insight into the inner working environment. Overall, we achieved a clearer picture of what our partners expect from us and how our project could benefit them.
Over the Easter break, we welcomed our fellow CDT students from the Universities of Sheffield, Manchester and Leeds for a short course in Practical Data Science in Python taught by Dr Dani Arribas-Bel. The course utilised a hands-on approach to help us grasp the steps involved when using datasets to solve real-life problems. These include data structuring, manipulation, visualisation, unsupervised learning algorithms and modelling. We also had the freedom to explore our own choice of datasets, giving each of us the opportunity to apply our new skills to topics that we find interesting and which relate to our PhD projects.
Overall, it was a valuable and transferable learning experience, which we very much enjoyed spending with our fellow Data CDT cohort. We will be looking forward to seeing everyone again for the final full-cohort module at the University of Sheffield in June.
Hi, we’re Noelyn, Jen, Oliver and Chris, the first Manchester cohort of the Data Analytics and Society CDT. We are based within the Social Statistics department at Manchester but are also part of the Data Science Institute; comprised of over 600 researchers and methodologists across the Science and Engineering; Humanities; and Biology, Medicine and Health Sciences faculties.
At Manchester, our partner organisations are the market research and data analytics firm YouGov; Medical Data Solutions and Services and the Burns and Plastic Surgery Service at the University Hospital South Manchester; The Greater Manchester Health and Social Care partnership; and the Vegetarian Society. It’s exciting to be part of a cohort working on diverse projects ranging from examining and predicting political attitudes by combining survey and social media data; using machine learning to predict and classify healthcare outcomes; developing data science methods of evaluating the impacts of devolving healthcare spending; and using survey and social media data to explore social and psychological influences on dietary choices.
While our research is still in its early stages, we are looking forward to carrying out internships at our partner organisations in the next couple of months and putting the data skills and knowledge we’ve been developing as part of the CDT into practice in a ‘real world’ context.
Recently all the CDT PhD students from Leeds, Sheffield, and Liverpool travelled to Manchester for the Understanding Data and Their Environment module. With Professor Mark Elliot from the Data Science Institute and Dr Nuno Pinto from Urban Design and Urban Planning, over a week we explored issues relating to data anonymisation and deidentification processes, security and disclosure control and the complex legal and ethical issues surrounding these.
Later in the week, with guidance from Dr Yu-wang Chen from the Alliance Manchester Business School we also learned a lot about data pre-processing methods, different approaches to linking databases and strategies for dealing with some of the inherent difficulties in data integration. We then had the opportunity to put our newfound skills into practise in group exercises looking at sales forecasting and classification for business analytics and combining socioeconomic data to look at factors which may affect life expectancy in London. Overall it was a challenging but enjoyable week – it was great to catch up with CDT students from the other universities and share our experiences of being PhD students so far, so we’re looking forward to the next CDT module in Liverpool in March.
The first semester of the Doctoral program has been busier than I think most of the Leeds cohort of the CDT were expecting. With commitments to a module on Research Methods, demonstrating courses for undergraduates and working on the assignments for Andy Evans’ programming module, each of us looked forward to the end of semester. With the end of term came an end to taught modules, as well as an outflux of the university’s undergraduate population. This also coincided with a visit from members of the Office of National Statistics, who operated a Safe Researcher Training course. The aim of the course was to educate on the ethics of working with social data, the risks involved and how these could be mitigated. The day-long course was very interactive, and was liberally scattered with group exercises that allowed us to further explore the ideas that were presented, as well as challenging our own preconceived ideas.
The end of term also freed up time to organize a first meeting with my external project partner – Leeds City Council. Up until this point, I had been predominantly focused on the academic aspects of my project – the mathematics, the programming, the data analysis – that my brain had been trained to see over the course of my degrees in Physics and Mathematics. However, it was at this meeting that it became immediately apparent how broad the scope of application of my work would be. This meeting also allowed for the discussion of the variety of data sources that would be available to me, as well as scoping out ideas for an internship project that I look forward to undertaking this semester.
Following the end of term, I travelled down to Cambridge to attend a training week run by the Academy for PhD Training in Statistics. The aim of the week was to provide two intensive courses: one on Statistical Computing and the other on Statistical Inference. This week brought together students from universities across the UK – a variety which was matched by the range of subjects in which students were doing their PhDs, from medical statistics to climate science. Learning such a volume of material in such a compressed time-period was quite a challenge, but the exceedingly high quality of lecturing and evening activities that had been organised helped to make the week a very enjoyable experience.
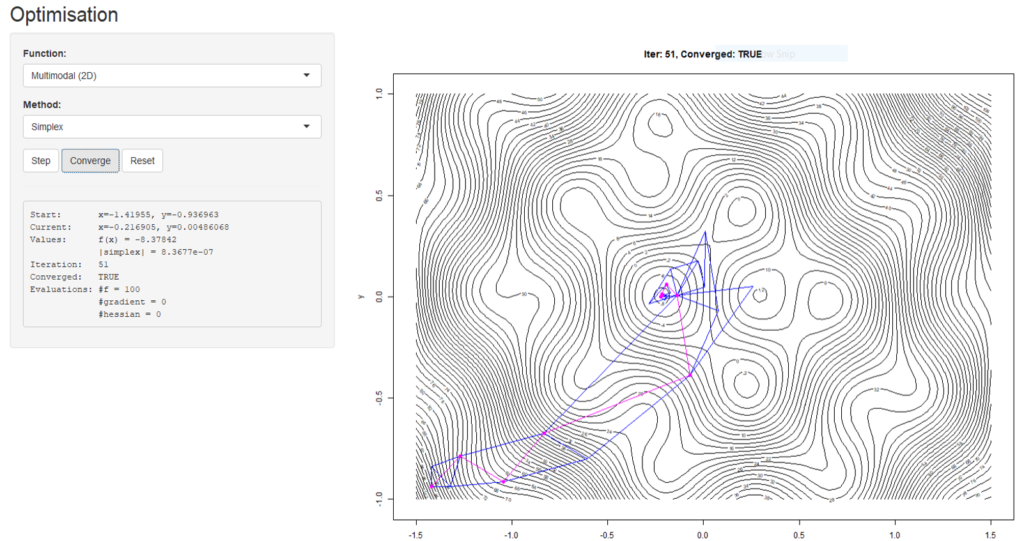
A Shiny app used on the Statistical Computing section of the courses in Cambridge, which was designed to examine the convergence of different numerical solvers.
Fortunately, this week was followed by the Christmas break – with the office closed over this period, we had no choice but to down our tools and take some well-earned rest (as well as polishing off a couple of assignments). Returning in the new year, we submitted our assignments and ventured over to Manchester for a week, where we met with the students from the other universities for the second of our joint modules. The topic of this week was Managing Data and Their Environment – a subject that we quickly learned encapsulated a wide variety of topics. The week was split into three parts: the first couple of days were devoted to the ethics and implications of using social data, the next couple of days focused more on the processes of data cleaning and linkage, and the final day was dedicated to a groupwork project whereby we could put into practice the ideas that we had learned about over the course of the week. The section on the usage of social data closely mirrored portions of the Safe Researcher Training course, and so many of the group found this to be a rather familiar exercise. The section on data cleaning and linkage, on the other hand, was found to be a little tougher owing to the volume of new information that we had to take in; I was fortunate to have spent a significant portion of the time that I was employed at Ampere Analysis working on data matching and linkage, however, there was still plenty of new material to absorb.
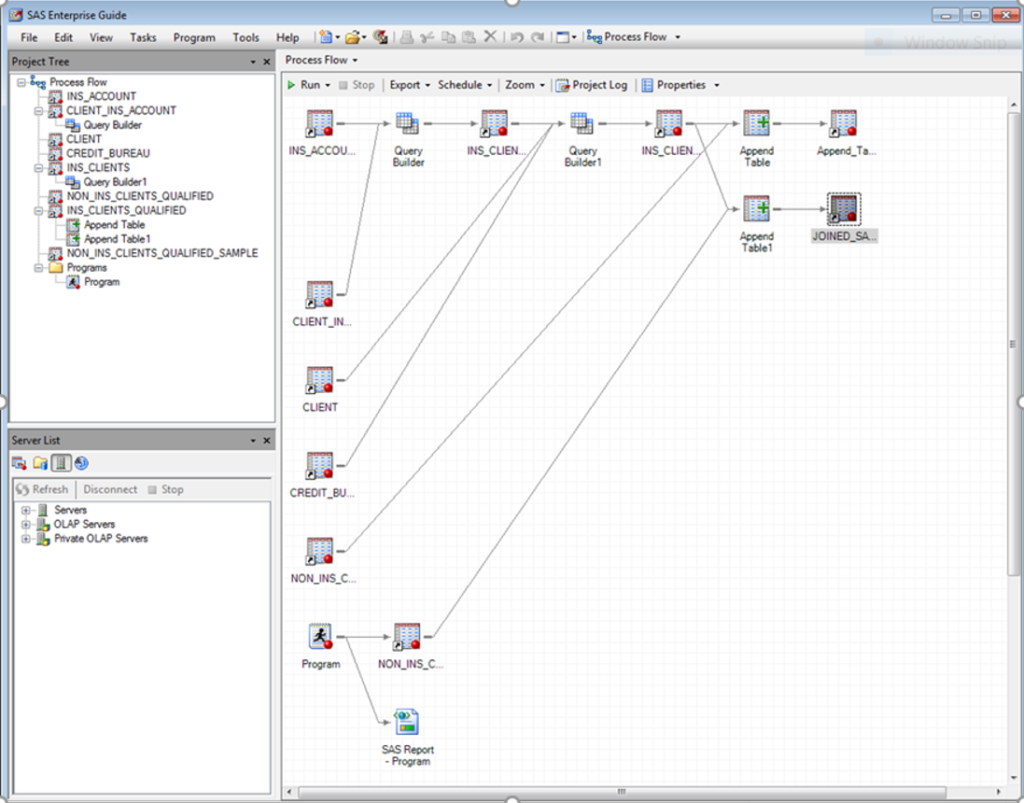
An example of the data flows created in SAS Enterprise Guide as part of the data cleaning and matching section of the Manchester module.
The challenges of the days were washed away by evenings spent exploring Manchester – the highlight of which was a visit to Tampopo where we enjoyed a variety of Asian food.
With the end of January comes the start of the second semester: a return to taught modules, supervisor meetings and demonstrating along with the new challenge of an internship with our respective project partners. This semester promises to be even busier than the last, however, I am sure that each of us are looking forward to the challenges that await us over the coming months.
Huge quantities of networked sensors have appeared in cities across the world in recent years. These include cameras and sensors that count the number of passers by, devices to sense air quality, traffic flow detectors, and even bee hive monitors. There are also large amounts of information about how people use cities on social media services such as Twitter and foursquare.
Citizens are even making their own sensors – often using smart phones – to monitor their environment and share the information with others; for example, crowd-sourced noise pollution maps are becoming popular. All this information can be used by city leaders to create policies, with the aim of making cities “smarter” and more sustainable.
But these data only tell half the story. While sensors can provide a rich picture of the physical city, they don’t tell us much about the social city: how people move around and use the spaces, what they think about their cities, why they prefer some areas over others, and so on. For instance, while sensors can collect data from travel cards to measure how many people travel into a city every day, they cannot reveal the purpose of their trip, or their experience of the city.
With a better understanding of both social and physical data, researchers could begin to answer tough questions about why some communities end up segregated, how areas become deprived, and where traffic congestion is likely to occur.
Difficult questions
Determining how and why such patterns will emerge is extremely difficult. Traffic congestion happens as a result of personal decisions about how to get from A to B, based on factors such as your stage of life, your distance from the workplace, school or shops, your level of income, your knowledge of the roads and so on.
Congestion can build locally at pinch points, placing certain sections of the city’s transport networks under severe strain. This can lead to high levels of air pollution, which in turn has a severe impact on the health of the population. For city leaders, the big question is, which actions – imposing congestion charges, pedestrianising areas or improving local infrastructure – would lead to the biggest improvements in both congestion, and public health.
The irony is, although modern technology has the power to collect vast amounts of data, it doesn’t always provide the means to analyse it. This means that scientists don’t have the tools they need to understand how different factors influence the way cities function and grow. Here, the technique of agent-based modelling could come to the rescue.
The simulated city
Agent-based modelling is a type of computer simulation, which models the behaviour of individual people as they move around and interact inside a virtual world. An agent-based model of a city could include virtual commuters, pedestrians, taxi drivers, shoppers and so on. Each of these individuals has their own characteristics and “rules”, programmed by researchers, based on theories and data about how people behave.
After combining vast urban datasets with an agent-based model of people, scientists will have the capacity to tweak and re-run the model, until they detect the phenomena they’re wanting to study – whether it’s traffic jams or social segregation. When they eventually get the model right, they’ll be able to look back on the characteristics and rules of their virtual citizens, to better understand why some of these problems emerge, and hopefully begin to find ways to resolve them.
For example, scientists might use urban data in an agent-based model to better understand the characteristics of the people who contribute to traffic jams – where they have come from, why they are travelling, what other modes of transport they might be willing to take. From there, they might be able to identify some effective ways of encouraging people to take different routes or modes of transport.
Seeing the future
Also, if the model works well in the present time, then it might be able to produce short-term forecasts. This would allow scientists to develop ways of reacting to changes in cities, in real time. Using live urban data to simulate the city in real-time could help to inform the managers of key services during periods of major disruption, such as severe weather, infrastructure failure or evacuation.
Using real-time data adds another layer of complexity. But fortunately, other scientific disciplines have also been making advances in this area. Over decades, the field of meteorology has developed cutting-edge mathematical methods, which allow their weather and climate models to respond to new weather data, as they arise in real time.
There’s a lot more work to be done before these methods from meteorology can be adapted to work for agent-based models of cities. But if they’re successful, these advancements will allow scientists to build city simulations which are driven by people – and not just the data they produce.
We would like to introduce ourselves; Vicki, Annabel, Jennie, Fran, Eugeni, Ryan and Keiran, as the first Leeds cohort of the Data Analytics and Society CDT. The CDT is funded by the ESRC and consists of students not only from the University of Leeds, but also the Universities of Sheffield, Manchester and Liverpool. The Data Analytics and Society CDT will run for four years and aims to train postgraduate researchers from a variety of backgrounds including social science, computing, mathematics and natural sciences in data analytics. The programme not only involves completing a PhD but also includes an integrated Masters in data analytics and society during the first two years of the course alongside the PhD work, so if we all suddenly get up and leave we are probably off to a lecture or practical.
We are carrying out a range of projects using datasets from commercial partners which include Active Inspirations, Leeds City Council, Callcredit and leading supermarkets. Between us we aim to use this data for a wide variety of health, commercial, safety and transport applications. From predicting and understanding human urban dynamics to apply to civil emergencies and understanding transport choices with regards to climate change. To assessing loyalty cards as a dietary assessment tool and spatial interaction modelling of E-commerce in the grocery retail industry and the behaviours affecting it. As well as predicting geodemographic segmentation throughout an individual’s lifetime, and using physical activity trackers to identify potential obesogenic habits and activities of individuals.
The First Few Weeks
As the CDT runs across four universities, as part of our masters, we all attend a week long module at each institution during our first year. Starting with the Leeds module in mid-September ‘Programming for Social Scientists’; a Python coding module run by Andy Evans. This was slightly daunting for a lot of the group with most people not having a coding background. However with Andy’s excellent teaching, and lots of coffee breaks, we managed to all build functioning agent based models and we were all still smiling on the Friday (as you can see in the photo above). Though we may have felt we were thrown in at the deep end with a week of python it was a great opportunity to meet the students from the other institutions. Helped by the delicious meal, and trip to the pub, organised by Eleri for the Monday evening allowing us to get to know each other better.
Having all met with our supervisors now and settled into LIDA, and cake Thursdays. We are now looking forward and starting to make exciting plans and goals for our future research as well as our next full-cohort module in Manchester this January.